Lecture 03 多处理器编程:从入门到放弃
入门
问题: 多处理器时代,Lecture 02 操作系统上的程序将的状态机的视角有什么变化?
前面讲的都是单线程,那怎么变成多线程 -> 并发程序的状态机模型
OSTEP对于并发的定义
Concurrent: existing, happening, or done at the same time.
In computer science, concurrency refers to the ability of different parts or units of a program, algorithm, or problem to be executed out-of-order or in partial order, without affecting the final outcome.
并且书中也提到了为什么将并发
- 操作系统是最早的并发程序之一
- 今天遍地都是 多处理器系统
并发的基本单位:线程Thread
其实从状态机的视角很容易能想到,如果我们有多个执行流什么需要多复制几份
在我们的状态机中,对于C语言的状态机,在虚拟内存中(因为在CSAPP中我学过),有放全局变量的地方,有堆区malloc可以在堆区申请空间,有栈区-栈帧, 寄存器, PC提供函数调用等
那其实很简单很自然的能想到,栈帧上的东西是局部变量,是自己的
所以在状态机中,是共享的全局变量,堆区,每个线程有自己的栈帧链
图
那怎么执行?并发体现在哪里?
外面像是有一个选择器,可以选择这个状态是t1执行还是t2执行;如果选择线程1执行,那就是把全局状态(全局变量和heap)+自己的局部状态当做是一个单线程的程序执行
链表变成树了 -- 每一部还是不确定的 蝴蝶效应?
图
简单的thread.h API
老师为大家封装了一个超级好用的线程API
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <stdatomic.h>
#include <assert.h>
#include <unistd.h>
#include <pthread.h>
#define NTHREAD 64
enum { T_FREE = 0, T_LIVE, T_DEAD, };
struct thread {
int id, status;
pthread_t thread;
void (*entry)(int);
};
struct thread tpool[NTHREAD], *tptr = tpool;
void *wrapper(void *arg) {
struct thread *thread = (struct thread *)arg;
thread->entry(thread->id);
return NULL;
}
void create(void *fn) {
assert(tptr - tpool < NTHREAD);
*tptr = (struct thread) {
.id = tptr - tpool + 1,
.status = T_LIVE,
.entry = fn,
};
pthread_create(&(tptr->thread), NULL, wrapper, tptr);
++tptr;
}
void join() {
for (int i = 0; i < NTHREAD; i++) {
struct thread *t = &tpool[i];
if (t->status == T_LIVE) {
pthread_join(t->thread, NULL);
t->status = T_DEAD;
}
}
}
__attribute__((destructor)) void cleanup() {
join();
}
wget https://jyywiki.cn/pages/OS/2022/demos/thread.h
这里面有两个核心的API,一个是create(), create是创建一个线程,创建一个入口函数是fn的线程(create的参数的类型是void* 函数指针)fn函数接受一个int的tid-线程号 -- create逻辑上做的就是上一个状态的pc+1了,然后又建立了一个新的状态链(tid=n,PC=0)
图
另一个函数叫join(), 假设T1执行了join, 在有其他线程未执行完时死循环,否则返回
记得编译的时候要额外加一个 -lpthread
接下来就是创建一个多线程的Hello World -- thread-hello.c
#include "thread.h"
void Ta() { while (1) { printf("a"); } }
void Tb() { while (1) { printf("b"); } }
int main() {
create(Ta);
create(Tb);
}
gcc -Og thread-hello.c -o thread-hello.out
./thread-hello.out
就会得到一个一直循环交替输出ab的结果,而且每次输出的个数都不一样
其实能看到create(Ta)和create(Tb)虽然是来个死循环,但是交替在执行,其实这里Ta可能放到了CPU1上,Tb可能放在了CPU2上
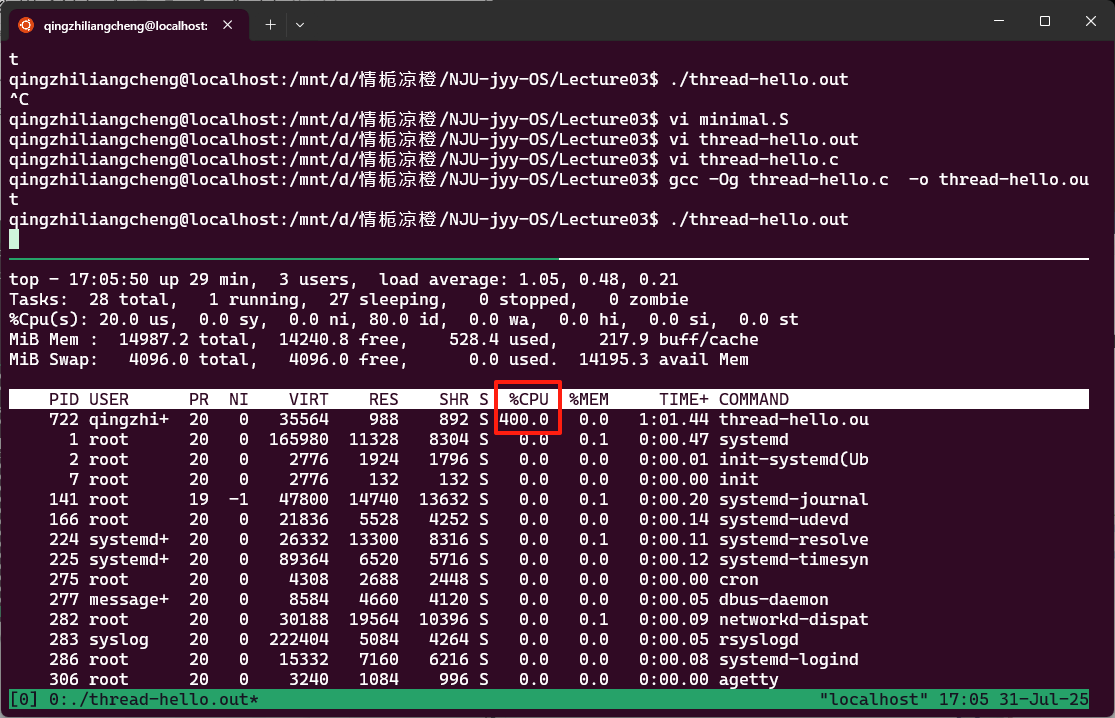
如果把Ta和Tb中的printf删掉 然后运行起来
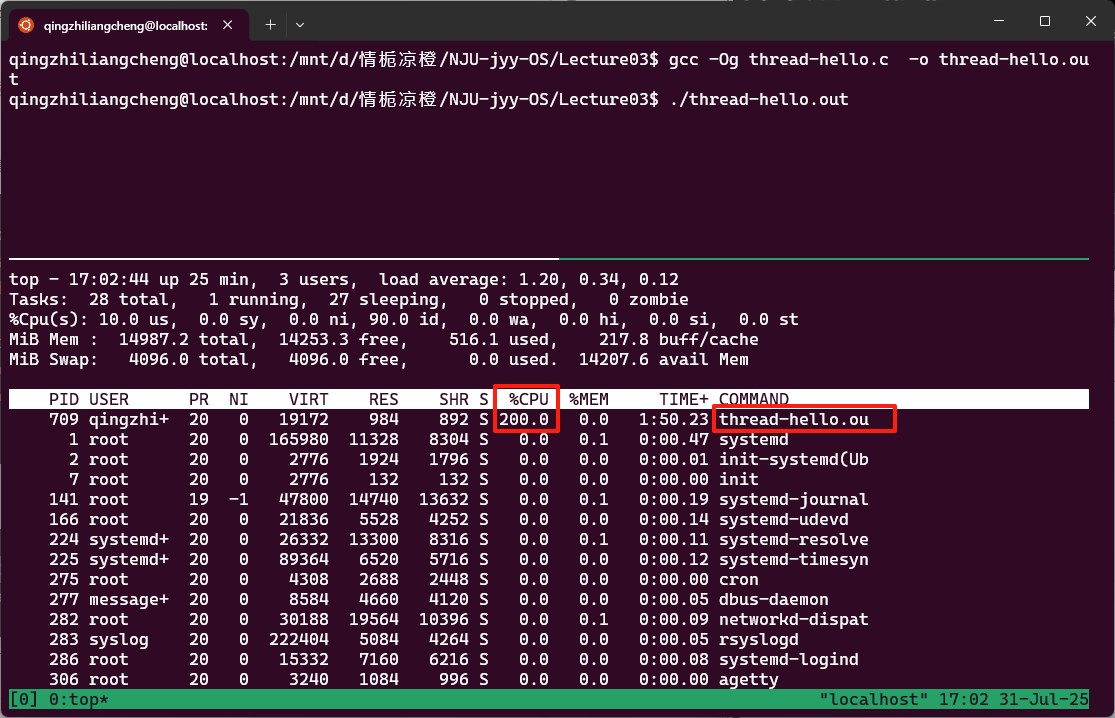
会发现thread-hello.out使用的cpu超过了100%
如果多创建几个呢? 创建4个 会占用到400%
这些所有的东西在同一地址空间里吗?
比如 我可以把一个线程定义一个局部变量,然后把这个局部变量存到一个全局变量里,然后看能不能其他线程能不能访问这个指针呢
共享内存了嘛?
如何证明线程确实共享内存 -- shm-test.c
#include "thread.h"
int x = 0;
void Thello(int id) {
usleep(id * 100000);
printf("Hello from thread #%c\n", "123456789ABCDEF"[x++]);
}
int main() {
for (int i = 0; i < 10; i++) {
create(Thello);
}
}

同样也能证明独立堆栈
同样的通过strace能看到哪个系统调用创建了线程
strace ./thread-hello.out
里面有个clone系统调用
这里的thread.h 线程库的背后 其实就是OSTEP中提到的POSIX Threads的封装
放弃1: 原子性
可怕的事情在逼近 -- 如果两个线程同时执行x++, 结果还对嘛
unsigned int balance = 100;
int Alipay_withdraw(int amt) {
if (balance >= amt) {
balance -= amt;
return SUCCESS;
} else { return FAIL; }
}
这在单线程是没有任何问题的
但是如果有两个线程
假设执行的顺序是: 当T1 PC=1 执行到if分支 而这时候执行的是T2 PC=1 那都会进if分支,而balance又是unsigned类型 hhh 那结果就是秒变土豪
其实因为我了解数据库内核 CMU15445的事务学了 这个是很了解的
#include "thread.h"
unsigned long balance = 100;
void Alipay_withdraw(int amt) {
if (balance >= amt) {
usleep(1); // unexpected delays
balance -= amt;
}
}
void Talipay(int id) {
Alipay_withdraw(100);
}
int main() {
create(Talipay);
create(Talipay);
join();
printf("balance = %lu\n", balance);
}
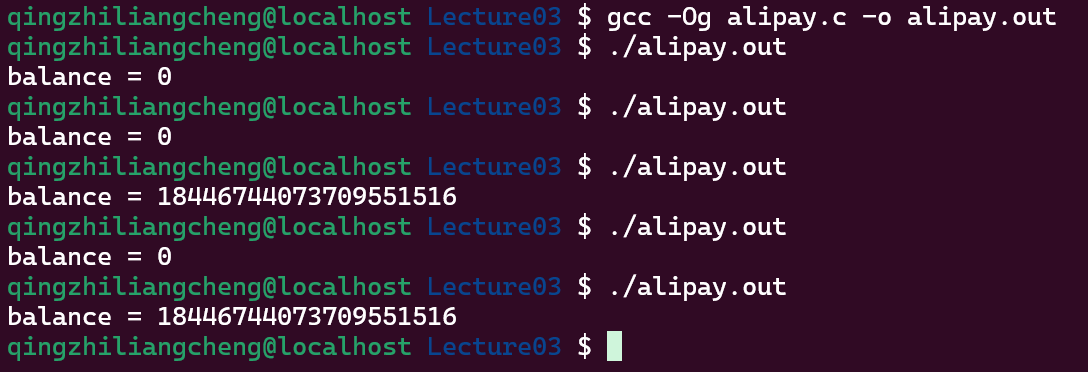
其实结果还是随机性的
类似的例子
#include "thread.h"
#define N 100000000
long sum = 0;
void Tsum() {
for (int i = 0; i < N; i++) {
sum++;
}
}
int main() {
create(Tsum);
create(Tsum);
join();
printf("sum = %ld\n", sum);
}
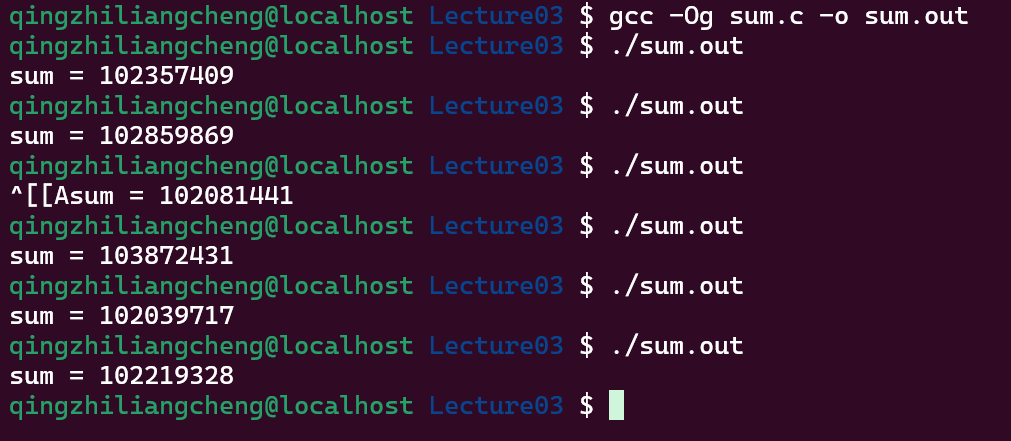
其实我们知道sum++这条指令实际上是三条指令
即便我们变成一条汇编指令
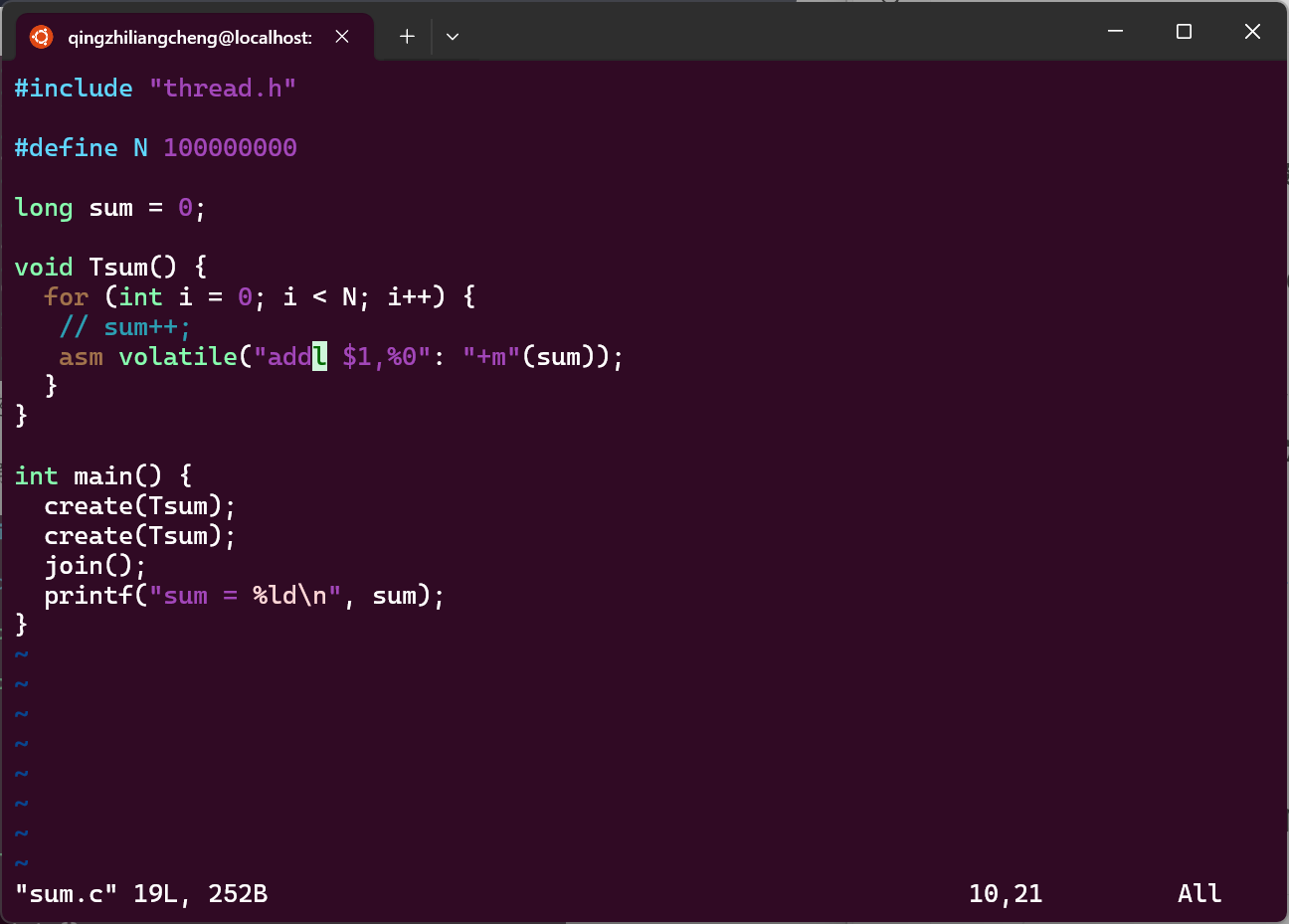
还是没有解决这个问题,直到加上lock
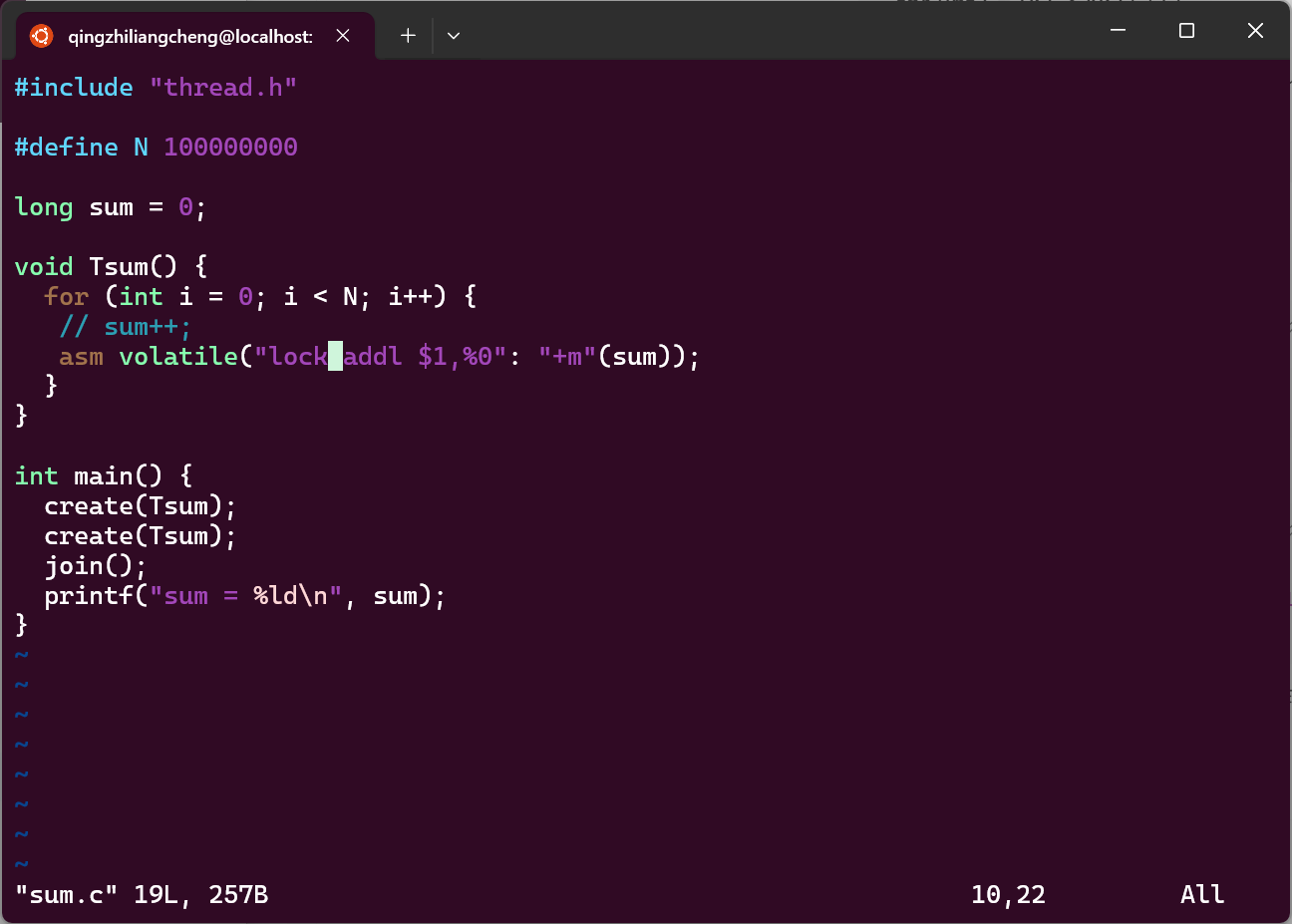
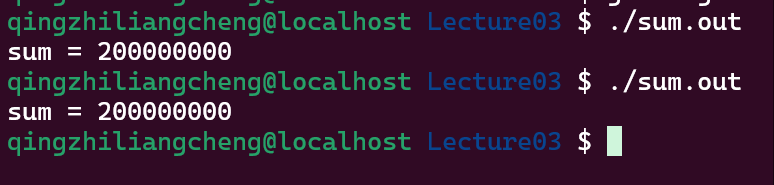
但是会发现运行速度显著下降
-> 丧失了原子性
但是我们都知道printf的原理是有缓冲区的
void thread1() { while (1) { printf("a"); } }
void thread2() { while (1) { printf("b"); } }
但执行这两个线程 炸不了
是因为 手册中说了 printf是 thread safety的
实现原子性
- lock
- unlock
放弃2: 顺序
还是sum.c
如果改变优化呢? 用O1和O2优化
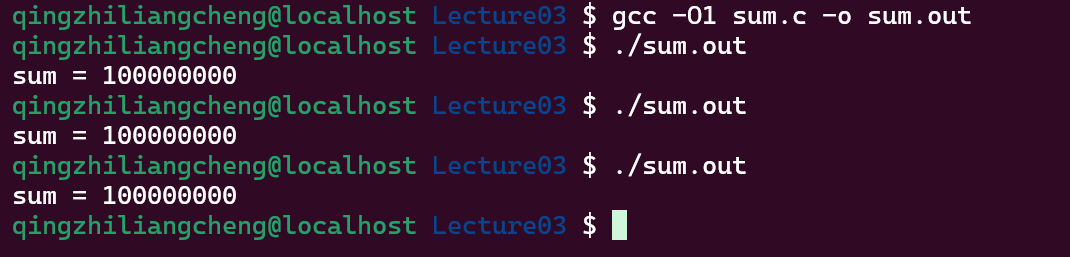
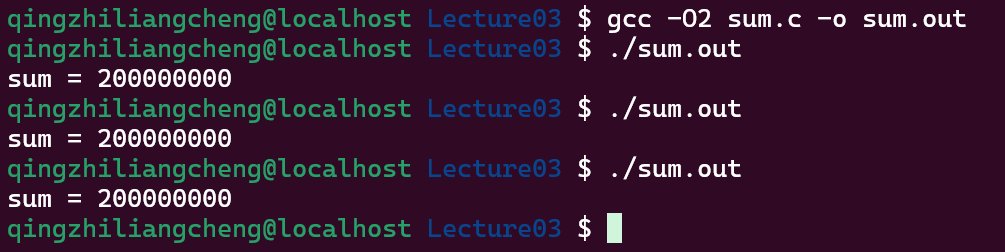
编译器的按照顺序单线程的程序来优化代码的
刚才的例子
-O1:R[eax] = sum; R[eax] += N; sum = R[eax]O1的情况两个线程都是这样的顺序,所以其实是给sum写了两遍100000000-O2:sum += N;给sum加了两遍
放弃3: 可见性
int x = 0, y = 0;
void T1() {
x = 1;
asm volatile("" : : "memory"); // compiler barrier
printf("y = %d\n", y);
}
void T2() {
y = 1;
asm volatile("" : : "memory"); // compiler barrier
printf("x = %d\n", x);
}
简单来说就是T1写x读y, T2写y读x
如果画个状态机的话,可能是0 1, 1 0, 1 1但无论如何不会得到0 0(因为不管是T1还是T2都会走一步)
wget https://jyywiki.cn/pages/OS/2022/demos/mem-ordering.c
这个代码很复杂 加了开关 加了原子的东西
开关初始是开开 然后交给两个线程 直到两个线程把开关关了 才停止
运行 会有0 0 出现 可是我们根据状态机的分析 不可能发生 0 0 这是为什么?
导致这个的原因是 处理器也是编译器 -- 我们看到的是objdump出来的那些指令 -- 但是实际上处理器在执行的时候 会通过电路翻译成更小的微指令微操作 -- 流水线乱序执行了 -- 可以并行执行多条小指令 只要数据依赖关系(可能维护的类似拓扑排序的东西) 没改就行
这是计算机体系结构的思想 -- 有一个指令的有向无环图,按照有向无环图来并行执行指令,然后就是木桶效应,哪里短板补哪里,内存满了加缓存……
# <-----------+
movl $1, (x) # |
movl (y), %eax # --+
单处理器的微指令尽可能优化成同时执行,第一条cache miss需要访存更多的时钟周期,本来同时执行的第二条指令反而先执行完
???